
6. Writing algorithms¶
6.1. Overview¶
As mentioned previously the framework makes use of the inheritance mechanism for specialising the Algorithm component. In other words, a concrete algorithm class must inherit from (“be derived from” in C++ parlance, “extend” in Java) the Algorithm base class.
In this chapter we first look at the base class itself. We then discuss what is involved in creating concrete algorithms: specifically how to declare properties, what to put into the methods of the IAlgorithm interface, the use of private objects and how to nest algorithms. Finally we look at how to set up sequences of algorithms and how to control processing through the use of branches and filters.
6.2. Algorithm base class¶
Since a concrete algorithm object is-an Algorithm object it may use all of the public and protected methods of the Algorithm base class. The base class has no protected or public data members, so in fact, these are the only methods that are available. Most of these methods are provided solely to make the implementation of derived algorithms easier. The base class has two main responsibilities: the initialization of certain internal pointers and the management of the properties of derived algorithm classes.
A part of the Algorithm base class definition is shown in Listing 6.1. Include directives, forward declarations and private member variables have all been suppressed. It declares a constructor and destructor; some methods of the IAlgorithm interface; several accessors to services that a concrete algorithm will almost certainly require; a method to create a sub algorithm, the two methods of the IProperty interface; and a whole series of methods for declaring properties.
6.3. Derived algorithm classes¶
In order for an algorithm object to do anything useful it must be specialised, i.e. it must extend (inherit from, be derived from) the Algorithm base class. In general it will be necessary to implement the methods of the IAlgorithm interface, and declare the algorithm’s properties to the property management machinery of the Algorithm base class. Additionally there is one non-obvious technical matter to cover, namely algorithm factories.
6.3.1. Creation (and algorithm factories)¶
A concrete algorithm class must specify a single constructor with the same parameter signature as the constructor of the base class.
In addition to this, a concrete algorithm factory must be provided. This is a technical matter which permits the application manager to create new algorithm objects without having to include all of the concrete algorithm header files. From the point of view of an algorithm developer it implies adding three lines into the implementation file, of the form:
#include "GaudiKernel/AlgFactory.h" // ... static const AlgFactory<ConcreteAlgorithm> s_factory; const IAlgFactory& ConcreteAlgorithmFactory = s_factory;where “ConcreteAlgorithm” should be replaced by the name of the derived algorithm class (see for example lines 10 and 11 in Listing 6.2 below).
6.3.2. Declaring properties¶
In general, a concrete algorithm class will have several data members which are used in the execution of the algorithm proper. These data members should of course be initialized in the constructor, but if this was the only mechanism available to set their value it would be necessary to recompile the code every time you wanted to run with different settings. In order to avoid this, the framework provides a mechanism for setting the values of member variables at run time.
The mechanism comes in two parts: the declaration of properties and the setting of their values. As an example consider the class TriggerDecision in Listing 6.2 which has a number of variables whose value we would like to set at run time.
The default values for the variables are set within the constructor (within an initialiser list). To declare them as properties it suffices to call the declareProperty() method. This method is templated to take an std::string as the first parameter and a variety of different types for the second parameter. The first parameter is the name by which this member variable shall be referred to, and the second parameter is a reference to the member variable itself.
In the example we associate the name “PassAllMode” to the member variable m_passAllMode, and the name “MuonCandidateCut” to m_muonCandidateCut. The first is of type boolean and the second an integer. If the job options service (described in Section 12.3) finds an option in the job options file belonging to this algorithm and whose name matches one of the names associated with a member variable, then that member variable will be set to the value specified in the job options file.
6.3.3. Implementing IAlgorithm¶
Any concrete algorithm must implement the three pure virtual methods initialize(), execute() and finalize() of the IAlgorithm interface. For a top level algorithm, i.e. one controlled directly by the application manager, the methods are invoked as is described in Section 5.7. This dictates what it is useful to put into each of the methods.
InitializationFig. 6.1 shows an example trace of the initialization phase.
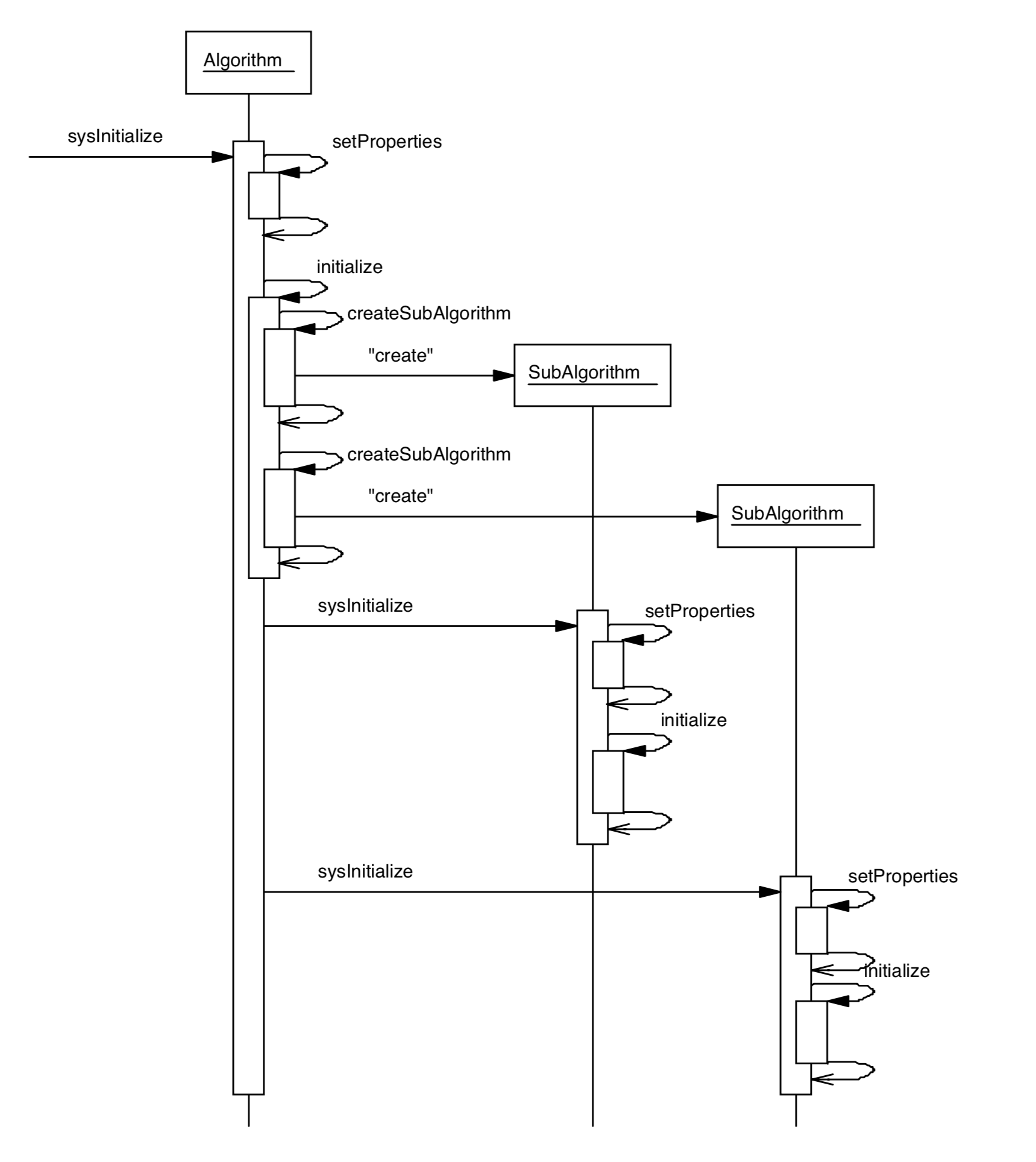
Fig. 6.1 Algorithm initialization¶
In a standard job the application manager will initialize all top level algorithms exactly once before reading any event data. It does this by invoking the sysInitialize() method of each top-level algorithm in turn, in which the framework takes care of setting up internal references to standard services and to set the algorithm properties (using the mechanism described in Section 12.3.1). At the end, sysInitialize() calls the initialize() method, which can be used to do such things as creating histograms, or creating sub-algorithms if required (sub-algorithms are discussed in Section 6.4). If an algorithm fails to initialize it should return StatusCode::FAILURE. This will cause the job to terminate.
ExecutionThe guts of the algorithm class is in the execute() method. For top level algorithms this will be called once per event for each algorithm object in the order in which they were declared to the application manager. For sub-algorithms (Section 6.4) the control flow may be as you like: you may call the execute() method once, many times or not at all.
Just because an algorithm derives from the Algorithm base class does not mean that it is limited to using or overriding only the methods defined by the base class. In general, your code will be much better structured (i.e. understandable, maintainable, etc.) if you do not, for example, implement the execute() method as a single block of 100 lines, but instead define your own utility methods and classes to better structure the code.
If an algorithm fails in some manner, e.g. a fit fails to converge, or its data is nonsense it should return from the execute() method with StatusCode::FAILURE. This will cause the application manager to stop processing events and end the job. This default behaviour can be modified by setting the <myAlgorithm>.ErrorMax job option to something greater than 1. In this case a message will be printed, but the job will continue as if there had been no error, and just increment an error count. The job will only stop if the error count reaches the ErrorMax limit set in the job option.
The framework (the Algorithm base class) calls the execute() method within a try/catch clause. This means that any exception not handled in the execution of an Algorithm will be caught at the level of sysExecute() implemented in the base class. The behaviour on these exceptions is identical to that described above for errors.
FinalizationThe finalize() method is called at the end of the job. It can be used to analyse statistics, fit histograms, or whatever you like. Similarly to initialization, the framework invokes a sysFinalize() method which in turn invokes the finalize() method of the algorithm and of any sub-algorithms.
Optionally, the methods beginRun() and endRun() can also be implemented. These are called at the beginning and the end of the event loop respectively.
Monitoring of the execution (e.g. cpu usage) of each Algorithm instance is performed by auditors under control of the Auditor service (described in Section 12.7). This monitoring can be turned on or off with the boolean properties AuditInitialize, AuditExecute, AuditFinalize.
The following is a list of things to do when implementing an algorithm.
· Derive your algorithm from the Algorithm base class.· Provide the appropriate constructor and the three methods initialize(), execute() and finalize().· Make sure you have implemented a factory by adding the magic two lines of code (see Section 6.3).
6.4. Nesting algorithms¶
The application manager is responsible for initializing, executing once per event, and finalizing the set of top level algorithms, i.e. the set of algorithms specified in the job options file. However such a simple linear structure is very limiting. You may wish to execute some algorithms only for specific types of event, or you may wish to “loop” over an algorithm’s execute method. Within the Gaudi application framework the way to have such control is via the nesting of algorithms or through algorithm sequences (described in section 5.5). A nested (or sub-) algorithm is one which is created by, and thus belongs to and is controlled by, another algorithm (its parent) as opposed to the application manager. In this section we discuss a number of points which are specific to sub-algorithms.
In the first place, the parent algorithm will need a member variable of type Algorithm* (see the code fragment below) in which to store a pointer to the sub-algorithm.
The sub-algorithm itself is created by invoking the createSubAlgorithm() method of the Algorithm base class. The parameters passed are the type of the algorithm, its name and a reference to the pointer which will be set to point to the newly created sub-algorithm. Note that the name passed into the createSubAlgorithm() method is the same name that should be used within the job options file for specifying algorithm properties.
The algorithm type (i.e. class name) string is used by the application manager to decide which factory should create the algorithm object.
The execution of the sub-algorithm is entirely the responsibility of the parent algorithm whereas the initialize() and finalize() methods are invoked automatically by the framework as shown in Fig. 6.1. Similarly the properties of a sub-algorithm are also automatically set by the framework.
Note that the createSubAlgorithm() method returns a pointer to an Algorithm object, not an IAlgorithm interface. This means that you have access to the methods of both the IAlgorithm and IProperty interfaces, and consequently as well as being able to call execute() etc. you may also change the properties of a sub-algorithm during the main event loop as explained in Section 12.3.2. Note also that the vector of pointers to the sub-algorithms is available via the subAlgorithms() method.
6.5. Algorithm sequences, branches and filters¶
A physics application may wish to execute different algorithms depending on the physics signature of each event, which might be determined at run-time as a result of some reconstruction. This capability is supported in Gaudi through sequences, branches and filters. A sequence is a list of Algorithms. Each Algorithm may make a filter decision, based on some characteristics of the event, which can either allow or bypass processing of the downstream algorithms in the sequence. The filter decision may also cause a branch whereby a different downstream sequence of Algorithms will be executed for events that pass the filter decision relative to those that fail it. Eventually the particular set of sequences, filters and branches might be used to determine which of multiple output destinations each event is written to (if at all). This capability is not yet implemented but is planned for a future release of Gaudi.
A Sequencer class is available in the GaudiAlg package which manages algorithm sequences using filtering and branching protocols which are implemented in the Algorithm class itself. The list of Algorithms in a Sequencer is specified through the Members property. Algorithms can call setFilterPassed( true/false ) during their execute() function. Algorithms in the membership list downstream of one that sets this flag to false will not be executed, unless the StopOverride property of the Sequencer has been set, or the filtering algorithm itself is of type Sequencer and its BranchMembers property specifies a branch with downstream members. Please note that, if a sub-algorithm is of type Sequencer, the parent algorithm must call the resetExecuted() method of the sub-algorithm before calling the execute() method, otherwise the sequence will only be executed once in the lifetime of the job!
An algorithm instance is executed only once per event, even if it appears in multiple sequences. It may also be enabled or disabled, being enabled by default. This is controlled by the Enable property. Enabling and disabling of algorithm instances is a capability that is designed for a future release of Gaudi that will include an interactive scripting language.
The filter passed or failed logic for a particular Algorithm instance in a sequence may be inverted by specifying the :invert optional flag in the Members list for the Sequencer in the job options file.
A Sequencer will report filter success if either of its main and branch member lists succeed. The two cases may be differentiated using the Sequencer branchFilterPassed() boolean function. If this is set true, then the branch filter was passed, otherwise both it and the main sequence indicated failure.
The following examples illustrate the use of sequences with filtering and branching.
6.5.1. Filtering example¶
Listing 6.3 is an extract of the job options file of the AlgSequencer example: a Sequencer instance is created (line 2) with two members (line 5 ); each member is itself a Sequencer, implementing the sequences set up in lines 7 and 8, which consist of Prescaler, EventCounter and HelloWorld algorithms. The StopOverride property of the TopSequence is set to true, which causes both sequences to be executed, even if the first one indicates a filter failure.
The Prescaler and EventCounter classes are example algorithms distributed with the GaudiAlg package. The Prescaler class acts as a filter, passing the fraction of events specified by the PercentPass property (as a percentage). The EventCounter class just prints each event as it is encountered, and summarizes at the end of job how many events were seen. Thus at the end of job, the Counter1 instance will report seeing 50% of the events, while the Counter2 instance will report seeing 10%.
Note the same instance of the HelloWorld class appears in both sequences. It will be executed in Sequence1 if Prescaler1 passes the event. It will be executed in Sequence2 if Prescaler2 passes the event only if Prescaler1 failed it.
6.5.2. Sequence branching¶
Listing 6.4 illustrates the use of explicit branching. The BranchMembers property of the Sequencer specifies some algorithms to be executed if the algorithm that is the first member of the branch (which is common to both the main and branch membership lists) indicates a filter failure. In this example the EventCounter instance Counter1 will report seeing 80% of the events, whereas Counter2 will report seeing 20%.
Listing 6.5 illustrates the use of inverted logic. It achieves the same goal as the example in Listing 6.4 through use of two sequences with the same instance of a Prescaler filter, but where the second sequence contains inverted logic for the single instance.